
K-Nearest Neighbors Classifier from Scratch
In the Applied Machine Learning class that I am in, our instructors have tasked us with building a K-NN classifier from scratch. No SKLearn, no pandas. I was really excited by this challenge, because I want to take my career in the direction of machine learning and its applications; I am keen to dig into the algorithm’s engineering so that I have a better understanding of the inner-workings. I’ll tell ya, I never realized how much of a crutch pandas and SKLearn together are for me, but this project was revealing, in a good way. Using solely Numpy was certainly tough but I think this exercise made me a better programmer. It also makes me excited for the weeks ahead, as I know I have a long way to go!
The instructors were kind enough to give us a nice beginning structure to be fair (shoutout to Prof. Shanahan and AIs Falconi and Shubham!) … but still I think I put a fair amount of work into it - especially the hours I spent troubleshooting my weak Numpy skills, ha! But I’m proud of it nonetheless!
The code block below is where I defined the object-oriented structure. It uses the familiar fit/predict paradigm that SKLearn uses, as well as a built-in scoring method that returns the accuracy. Continuing on in this notebook, I’ll use the Iris dataset to train and test the model. I’ll keep track of the accuracy in a pandas dataframe and plot the accuracy when I adjust the number-of-neighbors hyperparameter.
If you spot any irregularities/inefficiencies/mistakes, please let me know! I want to get better and learn as much as I can. Thank you for taking the time to look this over!
import numpy as np
from sklearn import datasets
class AndyKNNClassifier(object):
def __init__(self, n_neighbors=5, p=2):
self.n_neighbors = n_neighbors
self.p = p
self._train_objects = np.array([])
self._train_labels = np.array([])
def _metric_func(self, x1, x2):
"""
Return distance between two objects in Lp metric
Args:
x1(ndarray): first object
x2(ndarray): second object
Return:
distance(float): Lp distance
between x1 and x2 AKA Minkowski distance
"""
distance = np.linalg.norm(x1 - x2, ord = self.p, axis = 1)
return distance
def _accuracy(self, y_true, y_pred):
"""
Return the accuracy error measure
Args:
y_true(ndarray): true labels
y_pred(ndarray): predicted labels
Return:
acc(float): accuracy
"""
acc = np.sum(y_pred == y_true)/ y_true.shape[0]
return acc
def fit(self, X, y):
"""
Fits the KNN classification model, which is basically just
storing the data
Args:
X(ndarray): objects to train on
y(ndarray): labels for each object
Return:
self
"""
self._train_objects = X
self._train_labels = y
return self
def _nearest_neighbors(self, X):
"""
Get n nearest neighbors for each example in the dataset, X.
Returns two arrays that has a row for each example, and each entry
in that row are the nearest neighbors for that example.
First array are the indices of the neighbors, second
array are the distances of the neighbors
Args:
X(ndarray): objects
Return:
nearest_indices(ndarray): array of nearest
objects indices
nearest_distances(ndarray):array of nearest
objects distance
"""
nearest_dist_list = []
nearest_ind_list = []
for i in range(X.shape[0]):
obs = X[i,:]
distances = self._metric_func(self._train_objects, obs)
nearest_distances = np.sort(distances)[0:self.n_neighbors]
nearest_indices = np.argsort(distances)[0:self.n_neighbors]
nearest_dist_list.append(nearest_distances)
nearest_ind_list.append(nearest_indices)
return np.array(nearest_ind_list), np.array(nearest_dist_list)
def predict(self, X):
"""
Predict the label for new objects
Args:
X(ndarray): objects to predict
Return:
y(ndarray): labels for objects
"""
neighbors = self._nearest_neighbors(X)[0]
y = []
for row in neighbors:
labels = []
for i in row:
labels.append(self._train_labels[i])
labels_arr = np.array(labels)
pred_label = np.bincount(labels_arr).argmax()
y.append(pred_label)
return np.array(y)
def score(self, X, y):
"""
Return a dictionary which contains accuracy
Args:
X(ndarray): objects to predict
y(ndarray): true labels for objects
Return:
metrics(dict): dictionary which contains metrics,
for now only accuracy
"""
y_pred = self.predict(X)
acc = self._accuracy(y, y_pred)
metrics = {"acc": acc}
return metrics
Now that the model class has been defined, I’ll go ahead and import the Iris dataset and then split it into train and test splits. This will allow me to train the model and evaluate it using the “unseen” test data
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.30,
stratify = y,
random_state=42)
print(f"Preview of X_train: \n\n {X_train[0:6,:]}")
print(f"\n Preview of y_train: \n\n {y_train[0:6]}")
print(f"\n Shape of X_train: \n {X_train.shape}")
print(f"\n Shape of y_train: \n {y_train.shape}")
Preview of X_train:
[[5.1 2.5 3. 1.1]
[6.2 2.2 4.5 1.5]
[5.1 3.8 1.5 0.3]
[6.8 3.2 5.9 2.3]
[5.7 2.8 4.1 1.3]
[6.7 3. 5.2 2.3]]
Preview of y_train:
[1 1 0 2 1 2]
Shape of X_train:
(105, 4)
Shape of y_train:
(105,)
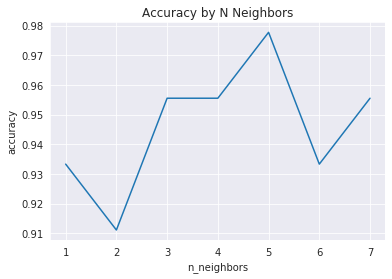
Now that I have the data ready, I will run a for loop to adjust the n_neighbors hyperparameter and see how the model performs. I’ll place the results into dataframe and then plot the results, which you can see below!
import pandas as pd
n_list = [1,2,3,4,5,6,7]
exp_log = pd.DataFrame(columns = ['n_neighbors', 'accuracy'])
for n in n_list:
knn = AndyKNNClassifier(n_neighbors=n, p=2)
knn.fit(X_train, y_train)
exp_log.loc[len(exp_log)] = [n, knn.score(X_test, y_test)['acc']]
exp_log
| n_neighbors | accuracy | |
|---|---|---|
| 0 | 1.0 | 0.933333 |
| 1 | 2.0 | 0.911111 |
| 2 | 3.0 | 0.955556 |
| 3 | 4.0 | 0.955556 |
| 4 | 5.0 | 0.977778 |
| 5 | 6.0 | 0.933333 |
| 6 | 7.0 | 0.955556 |
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
sns.lineplot(x='n_neighbors',
y='accuracy',
data = exp_log).set_title('Accuracy by N Neighbors')
So that’s it! It’s a basic implementation but I’m proud that I finally got it to work, using only Numpy! Once again, let me know your thoughts and thank you for taking the time to read through this. Take care!